Francisco Javier González Cańete
Generador de tráfico
Software
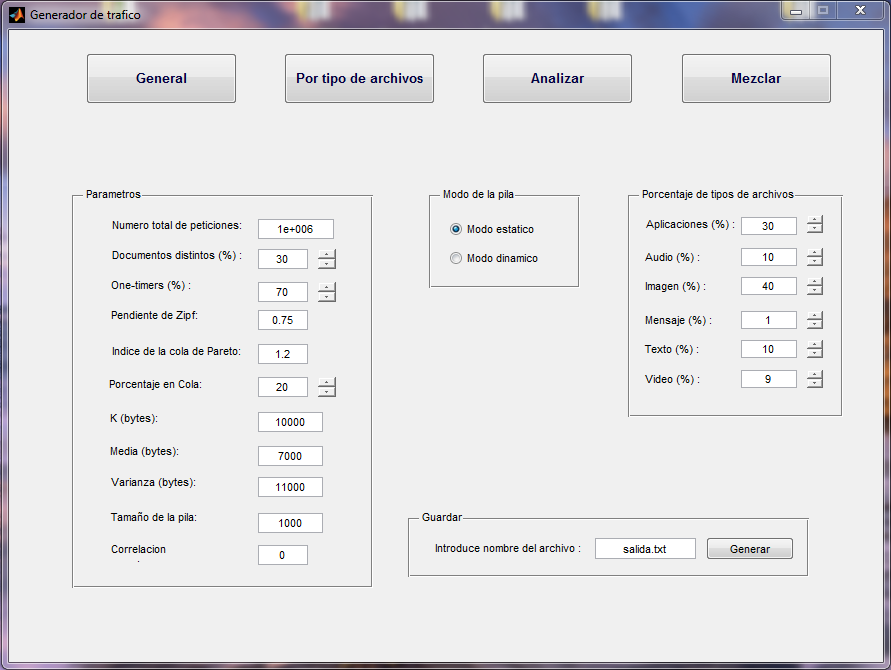
Se ha creado una herramienta sobre el entorno MATLAB que tiene como objetivo la generación de muestras de tráfico para su posterior procesado en simuladores de caché. El resultado de la aplicación es la creación de ficheros donde se especifican estas muestras de tráfico que serán las que utilicen posteriormente dichos simuladores.generador de tráfico incorpora cinco características de tráfico seleccionadas, las cuales han sido identificadas como importantes en estudios previos de muestras de tráfico en servidores: los documentos referenciados una sola vez, la popularidad de los documentos, la distribución del tamańo de los documentos, la correlación entre el tamańo de los documentos y su popularidad y, finalmente, la localidad temporal.
Documentos referenciados una sola vez (one-timers): El enfoque utilizado para modelar las referencias a documentos one-timers es determinar cuántos de los documentos distintos en la traza de tráfico a crear deberían ser one-timers. Utilizando el porcentaje de one-timers como un parámetro, se permite al usuario especificar el valor deseado. Una vez especificado, se puede hallar con facilidad el número de one-timers, con lo que las referencias a estos documentos se fijan a uno.
Popularidad de los documentos: Se ha usado la ley Zipf para modelar la popularidad de los documentos.
Distribución del tamańo de los documentos: Ésta se ha efectuado del siguiente modo:
- Se modela la cola de la distribución usando una distribución de Pareto.
- Se modela el cuerpo de la distribución usando una distribución logarítmica normal.
- Se unen ambas distribuciones.
Correlación entre el tamańo de los documentos y su popularidad: Las muestras de tráfico generado pueden tener correlación positiva, negativa o cero. Una correlación positiva implica que los documentos de mayor tamańo tienen mayor popularidad y correlación negativa implica que los documentos de menor tamańo tengan más probabilidad de ser requeridos (mayor popularidad). Mientras que correlación cero no otorga ninguna correlación entre la popularidad de los documentos y su tamańo. El hecho de permitir la existencia o no de correlación radica en la posibilidad de explorar distintos algoritmos de caché según cada una de estas opciones.
Localidad temporal: La aproximación utilizada para el modelado de la localidad temporal está basada en el modelo de pila finita LRU (Least Recently Used). Una pila LRU es una lista de todos los documentos ordenados según el momento de referencia, esto es, el último que haya sido referenciado estará en primer lugar de la pila y el que fue referenciado hace más tiempo estará en la última posición. La pila es actualizada dinámicamente cada vez que se procesa una referencia. En muchos casos, esta actualización implica el tener que ańadir un nuevo elemento en la cima de la pila empujando el resto hacia abajo, en otros casos, implica extraer un elemento existente en el interior de la pila y trasladarla a la cima de la misma, desplazando al resto de los elementos hacia abajo. Una pila LRU de tamańo finito es una pila LRU que sólo puede almacenar un número de documentos. El aspecto más importante en una pila LRU es que cada posición en la pila tiene asociada una probabilidad de referencia. Las probabilidades son asociadas a la posición de la pila y no a los documentos.
Tipos de documentos: Los documentos existentes en la Web se clasifican en función de su tipo en: aplicaciones, audio, imágenes, mensajes, texto y video. La aplicación desarrollada permite seleccionar el porcentaje de cada tipo de documentos que se desea generar. Además, permite la generación de muestras de tráfico para cada uno de los tipos de documentos especificando todos los parámetros anteriormente mencionados y posteriormente mezclar las muestras generadas para generar una muestra conjunta.